Миценко А.В., Анучкина О.Н.
ПРОГРАММНАЯ РЕАЛИЗАЦИЯ СИСТЕМЫ РАСПОЗНАВАНИЯ ИЗДЕЛИЙ ИЗ ДРАГОЦЕННЫХ МЕТАЛЛОВ НА СНИМКАХ ДОСМОТРОВЫХ РЕНТГЕНОТЕЛЕВИЗИОННЫХ АППАРАТОВ ПРИ ПРОВЕДЕНИИ ГОСУДАРСТВЕННОГО КОНТРОЛЯ
УДК 004.94:339.543
А.В. Миценко
студент факультета таможенного дела Ростовского филиала Российской таможенной академии
e-mail: nastua.mos@yandex.ru
О.Н. Анучкина
студент факультета таможенного дела Ростовского филиала Российской таможенной академии
e-mail: olyaanuchkina@mail.ru
Руководитель: Е.В. Алымова, кандидат технических наук, доцент кафедры
Аннотация. В статье представлены основные сведения об изображениях, получаемых с досмотровой рентгенотелевизионной техники, рассмотрены способы увеличения обучающей выборки и основные характеристики данного метода, определены особенности архитектуры нейросети, выбранной для классификации изображений.
Ключевые слова: информационные технологии, аугментация, искусственный интеллект, машинное обучение, нейросети, свёрточные сети.
Введение
В современных условиях деятельность таможенных органов во многом направлена на автоматизацию и развитие внешнеэкономической деятельности (далее – ВЭД). Использование искусственного интеллекта позволит автоматизировать и ускорить работу должностных лиц таможенных органов. Нейросети получили широкое распространение за счет того, что такая технология может обрабатывать большое количество данных, находить взаимосвязи, обучаться на примерах и исправлять ошибки.
Распознавание образов с применением технологий машинного обучения позволит выявлять незаконно перемещаемые товары быстрее и с большей точностью, что уменьшит время проверки декларации на товар, совершения таможенных операций, тем самым ускорит процесс осуществления таможенного контроля.
Цель статьи ‒ рассмотреть способы подготовки изображений для системы распознавания образов и архитектуру нейросети, которая позволит классифицировать изображения.
- Технология создания базы данных для проектирования свёрточной нейросети
Состав тестового материала в большей степени влияет на качество получаемого результата. Получение изображений отягощается такой технической проблемой, как подборка индивидуальных параметров для выборки.
В данной работе в качестве объекта исследования выбраны изображения с интроскопа Rapiscan. Rapiscan представляет собой рентгенотелевизионную систему досмотра ручной клади. Особенность получения изображений состоит в том, что каждая система имеет свои индивидуальные настройки, в частности, контрастность изображения. Однако, существуют общие принципы работы, такие как присвоение определенных цветов просвечиваемым материалам, багажа, грузов и т.п. Так, например, органические материалы на изображении выглядят оранжевыми, стекло и пластик – зелёными, а металлы – синими или черными.
Степень контрастности материалов также зависит от их строения: алюминий на изображении будет виден голубым или с синим контуром, золото и другие драгоценные материалы – черные с синевато-оранжевым свечением вокруг изделия [1].
Для обучения нейросети требуется большое количество данных. Данные должны быть однородными, непротиворечивыми, также они должны быть стандартизированы и нормализованы.
Для увеличения количества входных данных используется аугментация. Это один из ключевых инструментов улучшения качества нейросетей [2]. Встроенная в процесс обучения, она добавляет ему новые свойства, в том числе большую чувствительность сети к параметрам преобразований. Задача аугментации состоит в применении ряда преобразований к входному изображению. Примером использования аугментации являются изображения ювелирного изделия (золотых браслетов), представленные на рис.1.
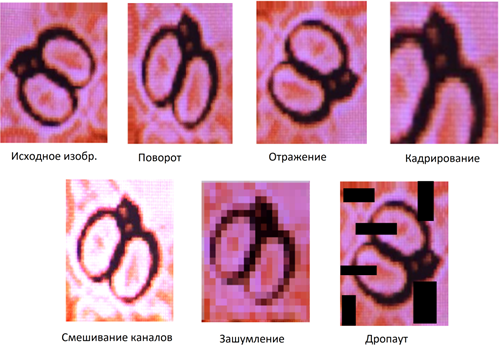
Рис. 1. Пример аугментации изображения ювелирного изделия
Стоит отметить, что, несмотря на удобство использования аугментации, в настоящее время она применяется непосредственно в процессе обучения. В этом случае вариативность данных не будет ограничена, после каждого запуска часть данных будет искажаться, что позволит увеличить объем выборки без потерь в объёмах памяти и скорости загрузки.
При использовании данного метода увеличения объема данных нужно учитывать, что параметры, необходимые для выборки, должны сохраняться из исходных изображений. Число параметров должно быть подобрано таким образом, чтобы сеть могла определять необходимые объекты даже на зашумленных или смазанных изображениях. Аугментация позволяет сократить чисто ошибок после обучения свёрточной сети почти на 10% [3].
Процесс обучения системы распознавания образов является кропотливым и требует большого количества данных. Основное различие между глубоким обучением и машинным обучением обусловлено тем, что данные представляются в систему.
2. Архитектура нейросети для классификации изображений
Важнейшим этапом в разработке программы классификации изображений товаров, перемещаемых физическими лицами, является определение типа и параметров нейросети, зависящих от характеристик обрабатываемых данных.
Для машинного обучения можно выбрать различные алгоритмы: всё будет зависеть от решаемой задачи. Так как в данном исследовании разрабатывается алгоритм, способный классифицировать произвольное изображение объекта из исходного множества, среди существующих задач машинного обучения рассматривается задача двоичной классификации (имеются только два варианта: изображение либо содержит, либо не содержит ювелирные украшения). А поскольку алгоритм обучается на подготовленной выборке изображений, то используется контролируемое машинное обучение.
При обучении сети ей предлагаются различные образцы с меткой, к какому типу их можно отнести. В качестве выборки используется вектор значений признаков. В этих условиях набор признаков должен позволять однозначно определить, с каким классом изображений имеет дело нейросеть.
При обучении важно научить сеть назначать не только достаточное количество и значение признаков, чтобы давать хорошую точность на новых изображениях, но и не переобучаться, то есть излишне «подгонять» результат под обучающую выборку из изображений [4]. После завершения правильного обучения нейросеть должна уметь определять образы (тех же классов), с которыми она не имела дела в процессе обучения.
Важно иметь в виду, что исходные данные для нейросети должны быть уникальными и непротиворечивыми, чтобы избежать ситуаций, когда работа нейросети может привести к тому, что объект будет принадлежать нескольким классам.
Существует несколько архитектур нейросетей, используемых в целях классификации. Однако на практике выбирают свёрточную нейросеть, преимуществами которой являются производительность, скорость обучения, способность автоматически определять важные характеристики в процессе обучения и др.
В представленном исследовании рассматривается модель свёрточной нейросети.
До начала реализации свёрточной нейросети необходимо загрузить библиотеки и изображения, с которыми производится работа (рис. 2).
Рис. 2. Библиотеки, необходимые для работы со свёрточной нейросетью
После этого необходимо удостовериться в том, что изображения, которые были загружены на Google диск, разархивированы и что к ним есть доступ (рис. 3).
Рис. 3. Часть разархивированных снимков
После загрузки снимков в среду разработки производится нормализация данных и преобразование правильных ответов в формат one hot encoding. При этом происходит создание двух признаков (по числу классов), один из которых равен нулю, а другой – 1.
Фрагмент кода свёрточной нейросети, использованной для реализации системы распознавания образов представлен на рис. 4.

Рис. 4. Фрагмент свёрточной нейросети
Количество используемых весов на входном слое достигает 7500 (50*50*3). Консольный вывод структуры нейросети, состоящий из:
а) входного свёрточного слоя («Conv2D»): отвечает за операцию свёртки и подбор ядер свёртки;
б) двух слоёв подвыборки («MaxPooling2D»): снижают размерность предыдущего слоя;
в) слоя преобразования данных из 2D представления в плоское («Flatten»): это вспомогательный слой, который позволяет перейти от свёрточной части сети, которая выделяет признаки из изображения, к полносвязной части НС, которая позволяет на основе выделенных ранее признаков произвести классификацию. Слой Dense принимает на вход вектор признаков, а не матрицу, поэтому слой Flatten преобразовывает формат матрицы, который нам передает свёрточный (пулинговый) слой, в формат вектора;
г) двух слоев («Dense») с параметрами функции активации («Activation») и слоями регуляризации, или случайными исключениями, («Dropout»): «Dense» – полносвязный слой, а «Dropout» предназначен для борьбы с переобучением. Данный слой снижает сложность нейросети за счет «отключения» заданного процента нейронов на каждом шаге обучения. Причем отключает он заданный процент каждый раз разных нейронов. Таким образом, каждый нейрон сети учится работать максимально самостоятельно, так как соседние нейроны могут исчезнуть в любой момент, и рассчитывать на их вклад в решение задачи нельзя.
Функция активации используют для введения нелинейности в нейросеть, что определяет выходное значение нейрона, которое будет зависеть от суммарного значения входов и порогового значения.
Также эта функция определяет, какие нейроны нужно активировать, и, следовательно, какая информация будет передана следующему слою. Благодаря функции активации глубокие сети могут обучаться.
Выводы
Таким образом, для системы классификации изображений товаров, перемещаемых физическими лицами, лучше всего подходит нейросеть со свёрточной архитектурой, поскольку она обладает возможностью анализировать не векторы, а двумерные массивы данных, которыми изображения и являются. Сама по себе свёрточная сеть не может справляться с задачей классификации объектов. Ее задача заключается в извлечении признаков, пространственных или цветовых. Для того чтобы строить какие-либо выводы по классификации объекта необходим полносвязный слой. Чтобы данная система могла обрабатывать выборку изображений, они проходят специальную обработку. Одним из приемов для увеличения обучающей выборки является аугментация, которая по своей сути является искусственным изменением изображений, путем трансформации размера, контрастности, яркости, масштаба, поворота и т.д. Использование аугментации должно быть аккуратным, чтобы при изменении изображения искомый класс оставался неизменным.
В ходе работы получен обучающий набор рентгеноскопических снимков содержимого ручной клади с ювелирными изделиями. Набор дополнен сгенерированными изображениями с различными преобразованиями (аугментация). Предложена архитектура свёрточной сети, решающей задачу бинарной классификации для обнаружения провозимых в багаже ювелирных изделий при таможенном контроле.
Программная реализация детектора ювелирных изделий на рентгеновских снимках багажа в зонах таможенного досмотра может использоваться как дополнительное программное обеспечение для досмотровой рентгенотелевизионной техники под управлением популярных операционных систем.
Использованные источники
1. Искусственный интеллект (ИИ) и машинное обучение [Электронный ресурс] // Службы облачных вычислений. Microsoft Azure. URL: https://azure.microsoft.com/ru-ru/overview/artificial-intelligence-ai-vs-machine-learning/#introduction (дата обращения: 21.02.2022).
2. Supporting an X-ray imaging system for customs control with AI and machine learning algorithms [Электронный ресурс] // Nexocode. Artificial Intelligience Development Company. URL: https://nexocode.com/ (дата обращения: 15.03.2022).
3. Programming tutorials Python [Электронный ресурс] // GitHub: where the world builds software. URL: https://gitub.com (дата обращения: 10.04.2022). 4. Программирование глубоких нейронных сетей на Python [Электронный ресурс] // Открытое образование. URL: https://openedu.ru/ (дата обращения: 12.04.2022).